Optimiza tus datos con ETL: Descubre la clave para una calidad impecable
La ciencia de datos es una disciplina que se dedica a extraer conocimiento y comprensión de un conjunto de datos mediante el uso de métodos científicos, algoritmos y sistemas de análisis. Es una combinación de habilidades en matemáticas, estadísticas, programación y dominio del dominio para extraer información valiosa de los datos.
En el mundo de hoy, donde la cantidad de datos que se generan es enorme, es crucial tener la capacidad de analizarlos y tomar decisiones informadas. Y una parte fundamental de este proceso es la etapa de Extracción, Transformación y Carga (ETL, por sus siglas en inglés).
La importancia del ETL en la ciencia de datos
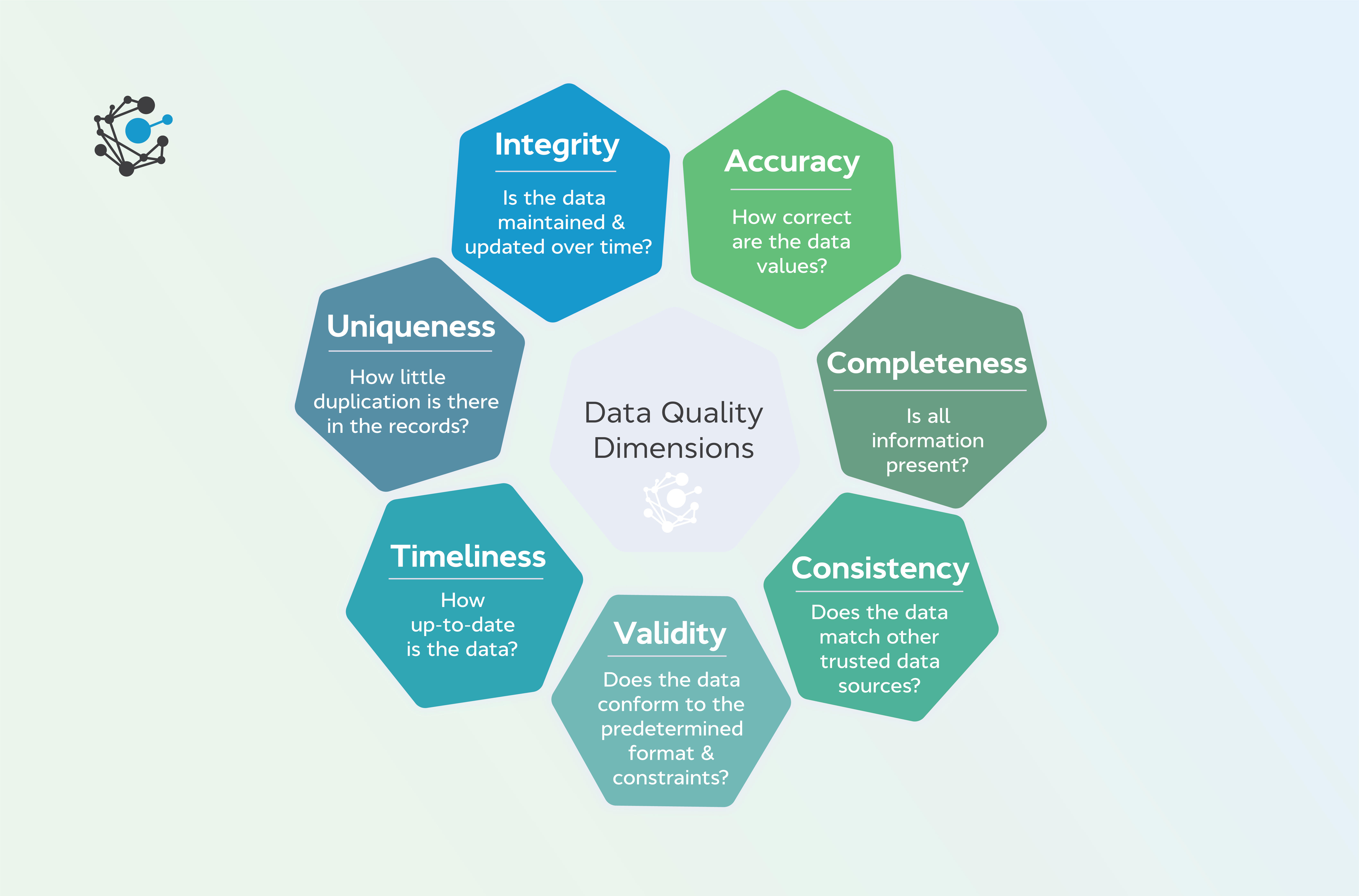
Uno de los mayores desafíos en la ciencia de datos es la calidad de los datos utilizados. Los datos pueden estar desorganizados, incompletos, contener errores o ser inconsistentes, lo que puede llevar a análisis incorrectos y decisiones erróneas.
Aquí es donde entra en juego el proceso de ETL. El ETL se encarga de realizar todas las tareas necesarias para garantizar la calidad de los datos utilizados en la ciencia de datos. Esto incluye la extracción de datos de múltiples fuentes, la transformación de los datos de acuerdo con las necesidades del análisis y la carga de los datos en un sistema de almacenamiento adecuado.
El ETL ayuda a limpiar y normalizar los datos, eliminando duplicados, corrigiendo errores y unificando formatos. Además, permite combinar datos de diferentes fuentes para obtener una imagen completa y precisa de la realidad. El ETL es un paso crucial en el proceso de la ciencia de datos, ya que garantiza que los datos utilizados sean de alta calidad y confiables.
Los componentes del proceso ETL
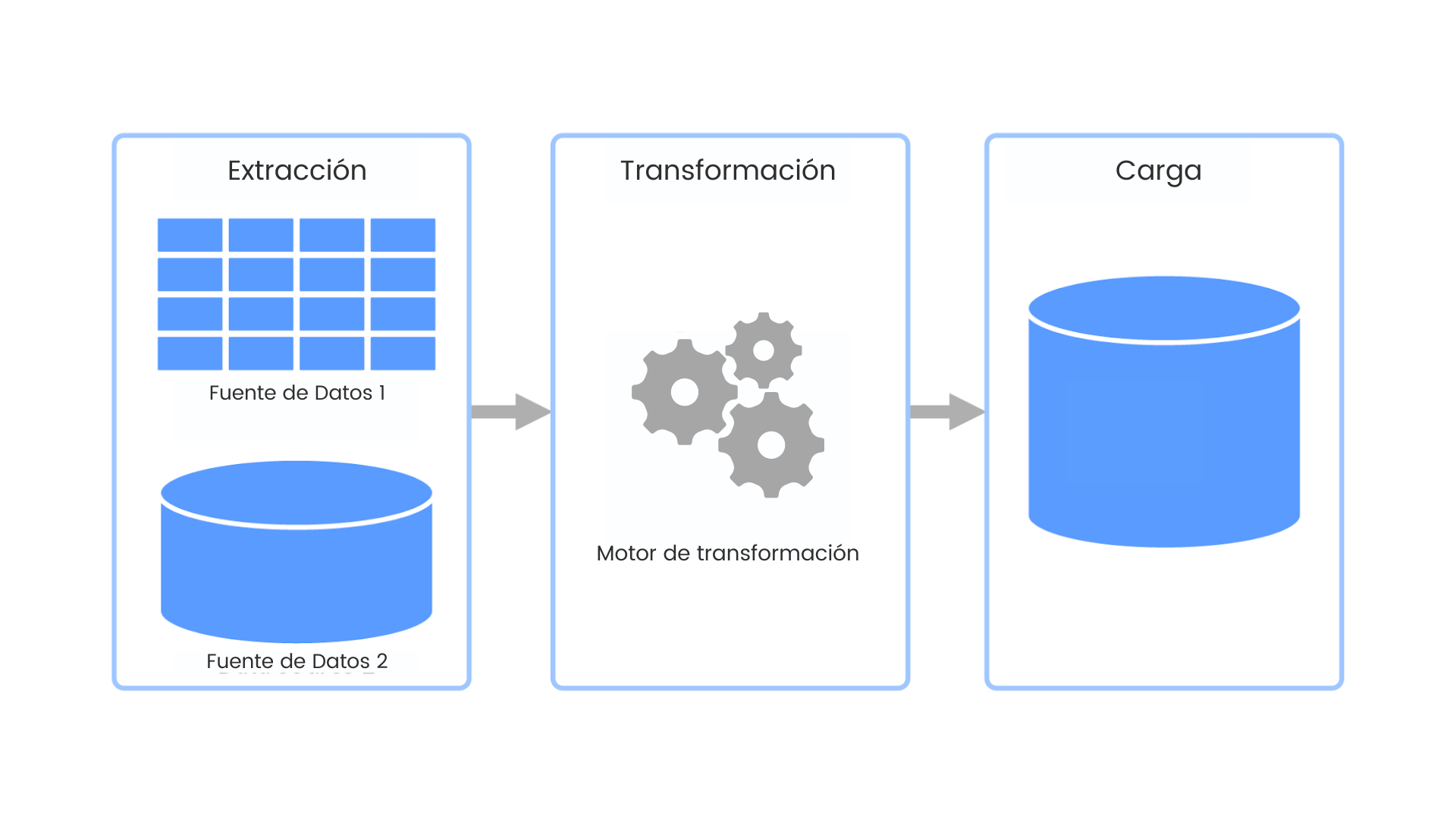
El proceso de ETL consta de tres componentes principales: la extracción, la transformación y la carga.
Extracción
En esta etapa, se recopilan los datos desde diferentes fuentes. Estas fuentes pueden ser bases de datos, archivos planos, sistemas de registro, APIs, entre otros. La extracción puede ser un proceso complejo, ya que implica obtener los datos de diferentes formatos y estructuras y convertirlos a un formato común para su posterior procesamiento.
Transformación
Una vez que los datos se han extraído, es necesario transformarlos para que se ajusten a los requisitos del análisis. Esto puede incluir la limpieza y normalización de los datos, la eliminación de valores duplicados o inconsistentes, la conversión de formatos y la creación de nuevas variables derivadas. La transformación de datos asegura que los datos sean coherentes y estandarizados para el análisis posterior.
Carga
Una vez que los datos se han transformado, se cargan en un sistema de almacenamiento adecuado, como un almacén de datos, un data lake o un sistema de gestión de bases de datos. La carga implica transferir los datos transformados al sistema de almacenamiento de manera eficiente y segura, manteniendo la integridad y la consistencia de los datos.
Te puede interesar...Arquitectura de Datos en la Gestión de Datos EmpresarialesLas herramientas y tecnologías utilizadas en el proceso ETL
Para llevar a cabo el proceso de ETL, se utilizan diversas herramientas y tecnologías que facilitan las tareas de extracción, transformación y carga de datos. A continuación, se presentan algunas de las herramientas más comunes utilizadas en la ciencia de datos:
Extract Transform Load (ETL) Tools
Estas son herramientas especializadas diseñadas para facilitar el proceso de ETL. Algunos ejemplos populares incluyen Apache NiFi, Talend, Pentaho y Microsoft SQL Server Integration Services (SSIS). Estas herramientas proporcionan interfaces gráficas intuitivas y funciones predefinidas para simplificar el desarrollo de flujos de trabajo de ETL.
Lenguajes de programación
Los lenguajes de programación como Python, R y SQL son ampliamente utilizados en la ciencia de datos y pueden ser utilizados para realizar tareas de ETL. Estos lenguajes proporcionan bibliotecas y funciones específicas para manipular y transformar datos de manera eficiente.
Bases de datos
Las bases de datos son fundamentales en el proceso de ETL, ya que son el destino final de los datos transformados. Bases de datos como MySQL, PostgreSQL y MongoDB son comúnmente utilizadas en la ciencia de datos y proporcionan funcionalidades avanzadas para almacenar y consultar datos de manera eficiente.
Herramientas de visualización de datos
Una vez que los datos han sido transformados y cargados en un sistema de almacenamiento, las herramientas de visualización de datos como Tableau, Power BI o matplotlib pueden ser utilizadas para visualizar y analizar los datos. Estas herramientas permiten crear gráficos, tablas y otros elementos visuales para representar los datos de manera clara y comprensible.
¿Cuáles son los beneficios del proceso de ETL en la ciencia de datos?
El proceso de ETL ofrece numerosos beneficios en la ciencia de datos. Algunos de los principales beneficios son:
Mejora la calidad de los datos
El proceso de ETL se encarga de limpiar, normalizar y combinar los datos de diferentes fuentes, lo que garantiza que los datos utilizados en el análisis sean de alta calidad y confiables. Esto mejora la precisión de los resultados y las decisiones basadas en los datos.
Aumenta la eficiencia del análisis
Al extraer, transformar y cargar los datos de manera adecuada, el proceso de ETL garantiza que los datos estén en un formato adecuado para el análisis. Esto facilita la manipulación y el procesamiento de los datos, lo que a su vez mejora la eficiencia del análisis y reduce los tiempos de respuesta.
Permite la integración de datos de diferentes fuentes
A menudo, los datos utilizados en la ciencia de datos provienen de diferentes fuentes, como bases de datos, archivos planos o sistemas de registro. El proceso de ETL permite combinar y unificar estos datos en un solo almacén de datos, lo que facilita su análisis y reduce la complejidad de trabajar con múltiples fuentes de datos.
Te puede interesar...Dashboard y calidad de los datos: ¡Aprende su importancia!Prepara los datos para el análisis avanzado
El proceso de ETL es una etapa fundamental para preparar los datos para técnicas de análisis avanzadas, como el machine learning. Al limpiar y transformar los datos de manera adecuada, el ETL permite que estos algoritmos se apliquen de manera efectiva y se obtengan resultados precisos.
Facilita la toma de decisiones informadas
Al garantizar la calidad de los datos utilizados en el análisis, el proceso de ETL proporciona una base sólida para la toma de decisiones informadas. Los análisis basados en datos confiables y de alta calidad permiten tomar decisiones más precisas y reducir el riesgo de decisiones erróneas.
Conclusión
El proceso de ETL juega un papel fundamental en la ciencia de datos al garantizar la calidad y la integridad de los datos utilizados en el análisis. A través de la extracción, transformación y carga de datos, el ETL mejora la calidad de los datos, aumenta la eficiencia del análisis, permite la integración de datos de diferentes fuentes, prepara los datos para el análisis avanzado y facilita la toma de decisiones informadas.
En un mundo donde la cantidad de datos es enorme, contar con un proceso de ETL sólido se vuelve esencial para extraer información valiosa y tomar decisiones informadas. Además, el ETL se beneficia de la utilización de herramientas y tecnologías específicas, como herramientas de ETL, lenguajes de programación y bases de datos.
El proceso de ETL es clave para una calidad de datos impecable en la ciencia de datos. Sin él, los análisis y las decisiones basadas en datos estarían en riesgo. Por lo tanto, es fundamental comprender y utilizar adecuadamente el ETL para aprovechar al máximo los datos y obtener un conocimiento valioso.
Preguntas frecuentes
¿Cuáles son las etapas del proceso ETL?
El proceso de ETL consta de tres etapas principales: extracción, transformación y carga. Durante la etapa de extracción, se recopilan los datos desde diferentes fuentes. En la etapa de transformación, los datos se modifican y se ajustan a los requisitos del análisis. En la etapa de carga, los datos transformados se cargan en un sistema de almacenamiento adecuado.
¿Qué herramientas se utilizan en el proceso de ETL?
Existen diversas herramientas para llevar a cabo el proceso de ETL. Algunas de las más comunes incluyen Apache NiFi, Talend, Pentaho y Microsoft SQL Server Integration Services (SSIS). Estas herramientas proporcionan interfaces gráficas intuitivas y funciones predefinidas para simplificar el desarrollo de flujos de trabajo de ETL.
¿Cuál es la importancia de la calidad de datos en la ciencia de datos?
La calidad de los datos es fundamental en la ciencia de datos, ya que afecta la precisión de los análisis y las decisiones basadas en ellos. Los datos de baja calidad pueden conducir a conclusiones incorrectas y decisiones erróneas. Por lo tanto, es crucial garantizar la calidad de los datos utilizados en la ciencia de datos, y el proceso de ETL desempeña un papel clave en este aspecto.
¿Cuáles son las ventajas de utilizar herramientas de ETL en el proceso de ETL?
El uso de herramientas de ETL proporciona numerosas ventajas en el proceso de ETL. Estas herramientas simplifican el desarrollo de flujos de trabajo de ETL, proporcionan interfaces gráficas intuitivas y funciones predefinidas, y facilitan la extracción, transformación y carga de datos. Las herramientas de ETL también pueden mejorar la eficiencia y la productividad al automatizar tareas repetitivas y complejas.
Te puede interesar...Data Quality